華為「韜定律」= Tau Scaling Law(τ 定律)
它不是傳統「摩爾定律」那種只靠製程從 7nm、5nm、3nm 繼續縮小,而是主張:
用「時間縮微」取代「幾何縮微」:縮短訊號與資料在晶片/系統中移動的時間 τ,來提升效能、密度與能效。
華為在 2026 年 5 月 25 日 ISCAS 2026 發表,稱可透過 LogicFolding/邏輯折疊、3D 堆疊、先進封裝、系統級協同 等方式,減少延遲與資料搬移成本。
-300x175.jpg)
最新AI半導體設計、製造、封測課程講義,立即註冊免費下載!

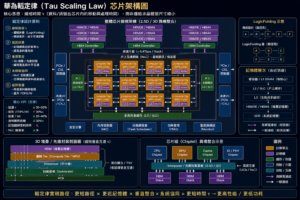
核心意思
項目
核心指標: 摩爾定律: 晶體管尺寸縮小 華為韜定律: 訊號傳播時間 τ 縮短
技術路線: 摩爾定律: EUV、先進製程 華為韜定律: 邏輯折疊、3D、Chiplet、封裝、系統協同
目標: 摩爾定律: 更多晶體管 華為韜定律: 更短延遲、更高能效、更高系統性能
對中國意義: 摩爾定律: 受 EUV 限制 華為韜定律: 嘗試繞開先進光刻瓶頸
白話解釋
以前比晶片先進程度,看「幾奈米」。
韜定律改成看:
資料從 A 點到 B 點要多久?能不能更短、更近、更快?
所以它強調:
少搬資料、縮短路徑、垂直堆疊、靠近記憶體、系統級最佳化。
評價
這是華為提出的「後摩爾時代」技術敘事,有戰略意義,但目前仍需要更多獨立實測數據驗證。路透也提到,華為未提供完整獨立性能數據;外界認為它是可行的工程方向。
「韜定律」轉成可落地的工程實作路線:從晶片架構、封裝、記憶體、互連、軟體排程到量測 KPI,避免只停留在概念。
華為「韜定律」實作方法
核心公式:
效能提升 = 縮短資料搬移時間 τ,而不是只縮小晶體管尺寸。
華為公開說法是從「幾何縮微」轉向「時間域縮微」,並以 LogicFolding、晶片間互連與系統級最佳化降低延遲;但外界仍認為需要更多獨立實測驗證。
1. 架構層:LogicFolding
把原本平面展開的邏輯路徑「折疊」成更短路徑。
傳統:
A → B → C → D → E
長線路、長延遲、功耗高
LogicFolding:
A → B
↓ ↓
D ← C
↓
E
短路徑、低延遲、低功耗
實作重點:
項目 做法
Critical Path 找出最長延遲路徑
Floorplan 把高頻互動模組靠近
Pipeline 拆短長組合邏輯
Retiming 重新配置 FF / Latch
Locality 資料就近處理
2. 記憶體層:Memory Near Compute
AI 晶片最大瓶頸不是算力,而是資料搬移。
傳統:
DRAM → Cache → Compute Core
資料搬很遠
韜定律:
HBM / SRAM / Cache 靠近 Compute Tile
資料搬更短
實作方式:
技術 目的
大容量 L2 / L3 Cache 減少外部記憶體存取
HBM3E / HBM4 提高頻寬
SRAM Tile 就近供資料
Data Reuse 同一批資料多次利用
Tensor Local Buffer 減少 DRAM round trip
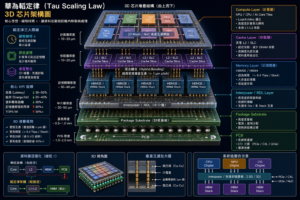
3. 封裝層:Chiplet + 2.5D / 3D
把 CPU、NPU、HBM、IO Die 放到更近的位置。
[Compute Die] [NPU Die] [IO Die]
\ | /
[Interposer / RDL]
|
[HBM]
實作重點:
技術 功能
CoWoS / 2.5D 縮短 Die-to-Die 距離
3D Stacking 垂直縮短互連
Hybrid Bonding 提高垂直互連密度
UCIe / NoC 標準化 Chiplet 互連
Advanced Substrate 降低 SI/PI 問題
4. 系統層:NoC 與資料流最佳化
韜定律不是只改晶片,而是改整個資料流。
CPU → NPU → Memory
改成:
Task Scheduler → 最近的 Compute Tile → 最近的 Memory Bank
實作方法:
層級 做法
NoC Routing 最短路徑傳輸
Task Scheduler 任務分配到最近核心
Compiler 資料搬移次數最小化
Runtime 動態調度 Cache / Memory
AI Model Mapping 模型分層對應硬體區塊
5. 量測 KPI
要驗證「韜定律」是否成功,不能只看 TOPS。
KPI 目標
τ latency 降低 30–50%
Energy / bit 降低 20–40%
Data movement distance 降低 30%+
TOPS/W 提升 30%+
Memory bandwidth utilization 提升
NoC congestion 降低
Cache hit rate 提升
6. 實作流程
Step 1:Profile workload
找出 AI 模型資料搬移瓶頸
Step 2:Identify τ bottleneck
量測 Core-to-Cache、Core-to-HBM、Die-to-Die 延遲
Step 3:Re-floorplan
把高互動模組靠近
Step 4:LogicFolding
重排邏輯與資料路徑
Step 5:Memory co-design
加大本地 SRAM / Cache / HBM proximity
Step 6:Chiplet packaging
用 2.5D / 3D / Interposer 縮短實體距離
Step 7:Compiler optimization
讓軟體知道資料應該放哪裡
Step 8:Measure τ again
用 latency、energy/bit、TOPS/W 驗證
一句話
韜定律實作 = 把資料路徑變短、把記憶體拉近、把邏輯折疊、把封裝立體化、把軟體排程改成「最短時間 τ」導向。
最新AI半導體設計、製造、封測課程講義,立即註冊免費下載!